Porting your code to Python 3
Alexandre Vassalotti <alexandre@peadrop.com>
Last Update: 2009-04-05
The following is a write-up of the presentation I gave to a group of Python developers at Montreal Python 5 on February 26th. This is basically a HTML-fied copy of the notes I prepared before the presentation. I haven't done editing, so expect a few grammar mistakes there and there. My complete presentation slides are available here. A video was taped should be released in the upcoming weeks (I will post a link here when I finally get my hands on it). Please note that if you're looking for more complete guide about Python 3 (and more accurate), I highly recommend that you read the What's New In Python 3.0 document and the Python Enhancement Proposals numbered above 3000.
You may wonder why we did Python 3 afterall. The motivation was simple: to fix old warts and to clean up the language before it was too late. Python 3 is not complete rewrite of Python; it still pretty much the good old Python you all love. But I am not going to lie. There are many changes in Python 3; many that will cause pain when you will port your code; and so many that I won't be able to cover them all in this talk. That is why I will focus only on the changes that will need to know to port your code. If you want to learn about all new and shiny features, you will need to visit the python.org's website and the online documentation of Python 3.
In the second part of this presentation, I will go over the steps needed to port a real library to Python 3. Hopefully, this part will give you a basic knowledge and tools to tackle the problems linked to the migration.
Finally, I will give you an insider's view of the upcoming changes in Python 3.1, which suppose to be released later this year.
Let's starts with the most obvious change in Python 3---that is print is
now function. Some people really don't like this change (mostly because it
makes hello world one character longer). But making print a function is
actually a good thing. First, it more flexible; you can now change the string
separator, pass print() as an argument or even override the
function completely.

In addition, the syntax is much cleaner---no weird >>sys.stderr
anymore. On other the hand, it is true that it takes a bit of time to get used
to the extra parentheses. Thankfully, converting your code to use the new
print() is easy and completely automated. You just run the 2to3
tool (I will talk more about 2to3 later) and you're done.

There is one thing special about the keyword arguments of
print(); they need to be explicitly written out. In other
words, they can only be supplied as keywords and never as a positional
argument.
This behavior is actually a new feature in Python 3, called keyword-only arguments. This is one of things that might surprise you when write new code with Python 3 (it did surprise me more once), since the error message is not that great. It makes sense from an implementation point-of-view, but not so much the user point-of-view. I hope someone will suggest something better in the future, but in mean time we have to live with this funky error message.
Keyword-only arguments are really useful when you have function that takes
a variable number of arguments and you want to add optional options to
it---just like print(). Another good use of this feature is for
forcing your API users to explicitly write out their intent. For example, this
is currently for the list.sort() method and
the sorted() function.

Finally, the syntax for making a function take keyword-only arguments is the following:

There is also a way to do the same thing in C, but that is out of scope of this presentation.
Now, let me introduce you the big change in Python 3: Unicode throughout. (Ed. There was a big applause when I announced this at Montreal Python. So, I guess the conversion pain did worth it.) This is huge; it took six Python Enhancement Proposals (PEPs, for short) to cover the changes related to Unicode. And I am pretty sure that not everything is covered in these. For this reason, I hope you will understand that I cannot cover everything today. So, what are these changes?

For one, all strings are Unicode by default. This means you cannot treat text as bytes, and vice versa, anymore. For example, if you read some bytes from disk or a network, you will need decide whether it is data or text; and this isn't always obvious. Is a filename data or text? Is command-line argument data or text? Or, is environment variables data or text? In many cases, Python core developers had to make compromises when converting the old APIs to Unicode.
So, let's examine the case of filenames. The first problem we run into is: how do we detect the character encoding used by the filesystem? There is no standard way of doing this that works on every platforms supported by Python. On MacOS X, life is simple; we just use UTF-8. On Windows, we can use the Wide API and things mostly work. On Unix however, the encoding can be anything. So, we cannot tell in advance what the encoding will be; we have to detect at runtime with langinfo API (if present). And this leads to some interesting bootstrapping issues, since some codecs in Python are not built-in. For example, there are known problems with Python scripts running from a directory whose path contains non-ASCII characters.
Another problem we run into is: what should we handle filenames encoded incorrectly? Even if we know that the filesystem uses UTF-8, that doesn't mean all filenames will be a valid UTF-8 byte sequence. In Unix for example, there is only nul and slash that cannot appear in a filename; so, it is possible to construct filenames that cannot be interpreted as a text string. And this is basically what I want to say; it is not always clear what is text and what is data. So in Python 3, most system APIs accept bytes as well as strings as a work-around.

However, the problems I have described are not as bad as it sounds. In most cases, the Unicode enhancements will lead to better code and also fewer bugs. And having Unicode throughout has opened the door for other internationalization improvements as well. One of these improvements is non-ASCII identifiers are now supported (but not advocated).


Another feature of Python 3 is the new I/O library designed with Unicode
in-mind. From a core developer's point of view, this change is fairly large: a
departure of C stdio and a brand-new I/O class hierarchy completely written in
Python (which is currently being rewritten in C for performance). However,
from the point of view a typical Python developer, there isn't much that has
changed. I/O still work the same as before; open() still return
file-like object, which an be written to and read from just like before.

But if you want more control over your I/O, now you can. Just import the io module, and use or derive a class that fits your needs. One nice thing about the new I/O is once you've defined the raw byte-based interface, you can easily add buffering and text-handling features.
Take for example a network socket. What can we do with a socket? Well, we can
read some bytes from it and maybe also write to it too. But, we cannot seek it
like a file. Usually, we call such objects streams. So, we can derive our
SocketIO class from io.RawIOBase and define our
methods. Need buffering? Just wrap an instance of SocketIO with
io.BufferedReader or io.BufferedWriter. Need
text-handling too? Well wrap your instance
with io.TextIOWrapper. And that's all there is to it.
If you're used to Java I/O libraries, this should sound fairly similar; and this is intentional. The main difference is the new I/O in Python simpler. If you want to learn more about the details the new I/O library, I encourage you to read the PEP and the online documentation.

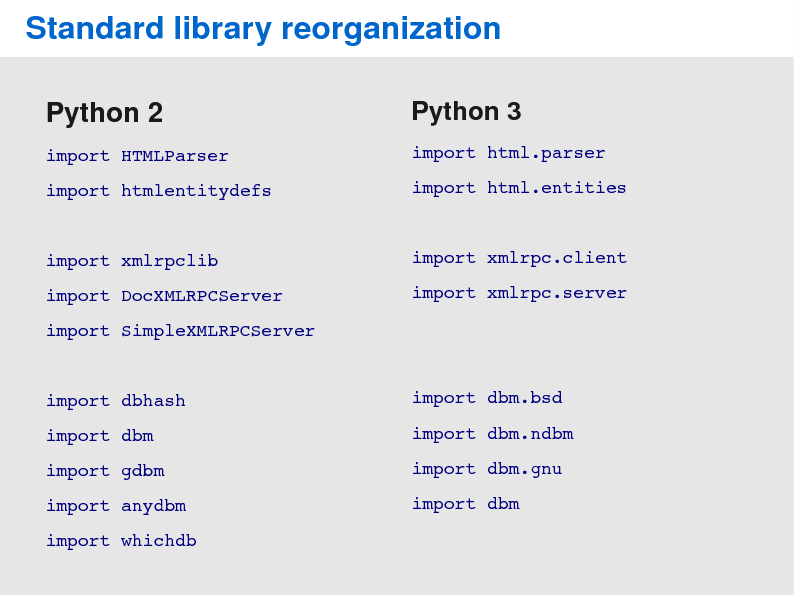
Now, let's talk about the change that will probably cause the most pain during the transition: the standard library reorganization. In Python 3, many modules were remove, renamed and repackaged. Initially, the reorganization was not part of the plans of Python 3. But since Python 3 was going to be backward-incompatible anyway, many developers (myself included) saw a chance to clean up the library and remove the silly old stuff all at once. So, instead of having many incompatible releases over time, we have big one.
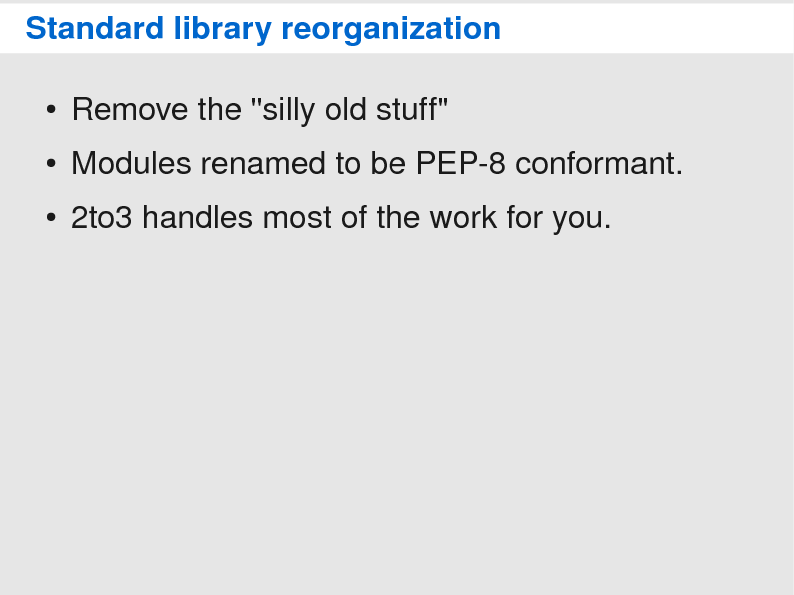
Thankfully, the 2to3 tool will handle almost all the work for you. Unfortuately, 2to3 won't help with removals. This means you will need to change your code to not use these before porting to Python 3. PEP 3108 documents all the changes we have done; it also suggests replacements for modules that were removed. So, this should be the first place to look at whenever you have a problem with a reorganized module.

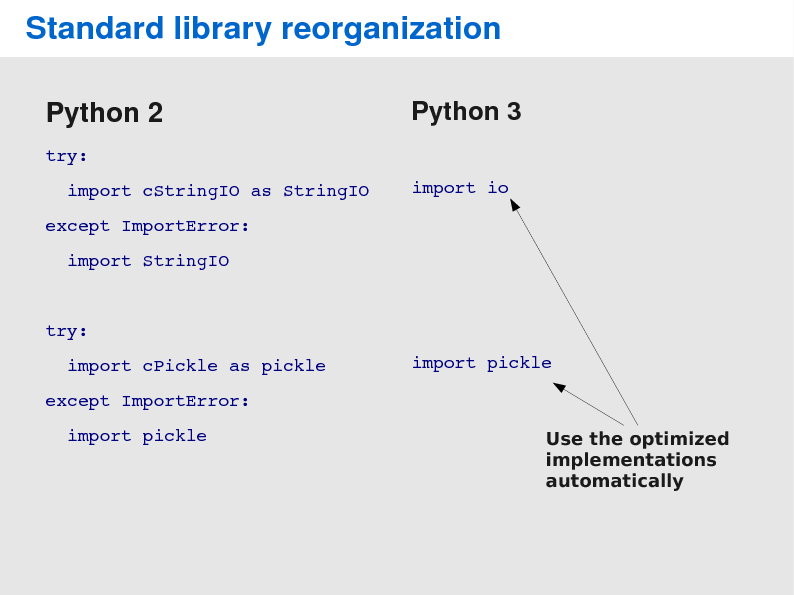

Also if you the pickle module, the standard library reorganization will make it hard for you to create pickle data streams that works both on Python 2 and 3. The problem is pickle saves class and function objects by named reference. This means if you have pickle data created with Python 2, in which a instance whose class was renamed in Python 3, pickle will not be able to recreate the instance in question. Unfortunately, there is nothing yet to help you with that problem. Although it is possible to subclass Unpickler and modify it to rewrite names on-the-fly, this is not very convenient.

In addition to stdlib reorganization, the behavior of some well known APIs has
changed. In particular, many methods that used to return lists, now return an
iterator or a view. For example, dict's keys(), items() and
values() (Ed. values() is not actually a
set-like object for the obvious reason that a dictionary may contain duplicate
values. This was an error from my part.) are no longer lists; they
return a set-like object called a view. Personnally, I found this change very
nice when working graphs implemented using dicts, because I could now use
standard set operations, like addition and subtraction, on the views.

Similarly, many built-in functions now return iterators instead of lists. This
is the case of map(), filter() and zip().
For map() and filter(), it is typically a good idea
to rewrite them as list-comprehension. Another change in the same line is
xrange() is the new range(). For most code, this
requires no modifications. Again, 2to3 handles these changes for you.

Continuing on API changes, some special methods have been removed or renamed.
For example, the next() method on iterators is now called
__next__(). To get the next item of an iterator, use the built-in
function next().
Also, __getslice__ and friends were removed in favor of
__getitem__.

The special methods __hex__ and __oct__ were
removed in favor of __index__(). Generally, this requires no
change in your code. Note, 2to3 will not remove the old methods.
Another fairly important change in Python 3 is the simplification of the rules
for ordering comparisons. So in Python 3, the old three-way comparison rules
has completely replaced by a much simpler (and faster too) mechanism
(Ed. There wasn't much rejoice when I presented this change. People kept
asking why Python doesn't generate comparison methods automatically from
__lt__ and __eq__).

Clearly, 2to3 won't translate old three-way compares, so you will need to support three-way and rich comparisons if you want your code to work both on Python 2 and 3. The changes needed are usually straightforward, so this generally not a problem.
We already saw that the syntax for the print statement and unicode string was changed. So, the remaining changes I want to talk about are the other syntactic changes in Python 3. For the most part, the new syntax niceties are also available in Python 2.6 has optional features; the difference in Python 3 is you're now required to use them. But don't worry, 2to3 will handle these changes fairly well. So what are these changes?
First, we have new syntax for catching and raising exceptions. In particular, the syntax for saving an exception was simplify to remove ambiguities.

Similarly, the syntax for raising exceptions was simplified. Note that all
exceptions must derive from BaseException or, more commonly, from the
Exception class. This was optional in Python 2; this is now enforced in Python
3. As a consequence of the new syntax, tracebacks must be new set explicitly
via the __traceback__ attribute. However if you need to do that,
you probably want to check out a new feature called exception chaining.
In Python 3, we also have new syntax for specifying metaclasses. To do so, we allowed keywords arguments in after base classes list in the class definition. Currently, this is only used to support the new metaclass syntax; but this could be used for other purposes, as well, as long the metaclass used supports it.
Continuing, relative imports now need to use the from-dot-package syntax. If you omit the dot, it will be interpreted as an absolute import.

Now, let me show you two lovely additions to Python 3: set and dict comprehension. But first, I need to introduce the new syntax for set literals.

We can almost guess what is the syntax set and dict comprehension.

So, we are now ready for the real thing: migrating to Python 3. There is more than one way to approach the migration and there is no approach that will fit all your needs. In many cases, you have to experiment and choose whatever work best for you. Also, I am only going to cover the issue of migrating Python code. If you want to migrate C extensions, you will need to check out the online documentation.
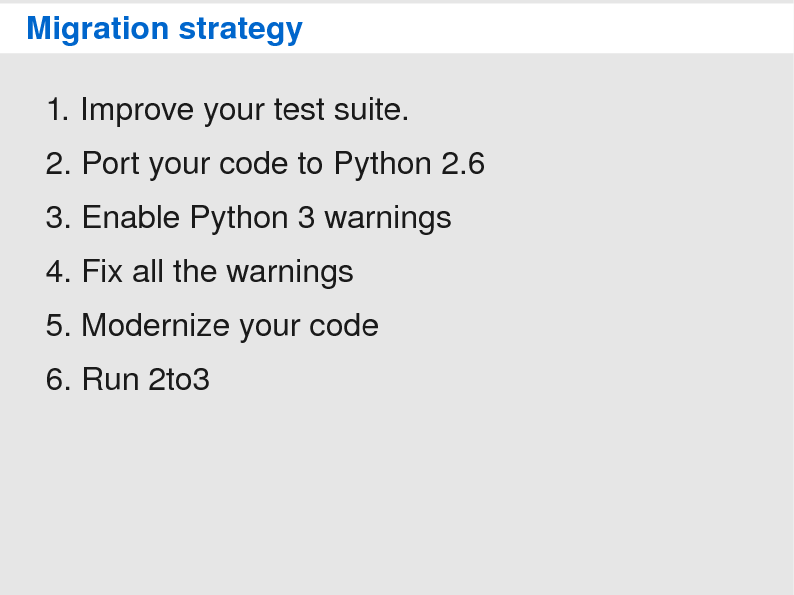
The very first step before migrating is to verify you have an excellent test coverage. If you do not have a test suite, it would be a good time to start investing time to create one. I wouldn't even think about migrating to Python 3 without test suite, since it is practically impossible to predict where your code is going to break.
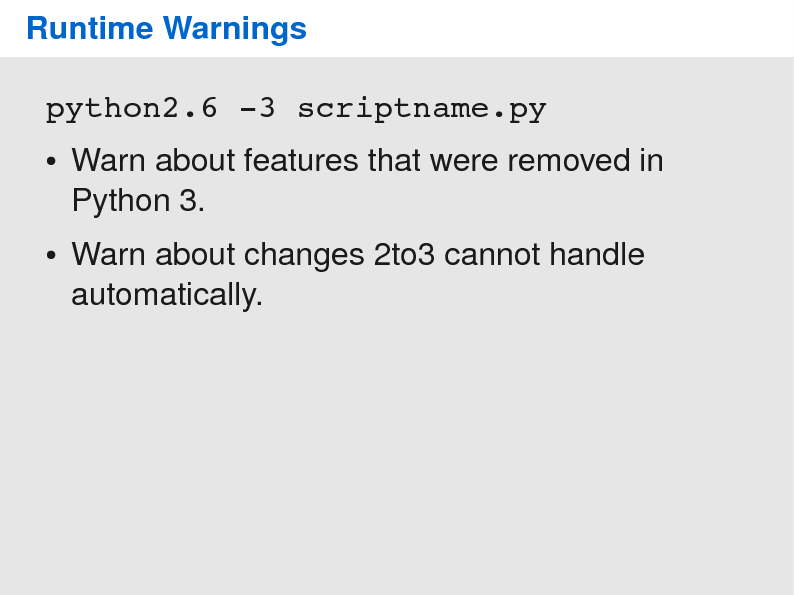
Once you verified your test suite was alright, you should begin by porting your code to Python 2.6; generally this is effortless. Then, turn on the -3 flag of Python 2.6. This will enable warnings about features that have been removed or changed in Python 3. Run your tests and fix all the warnings you see.

It is also a good idea to modernize your code at this stage; and try to reduce
the semantic gaps as much as possible. For example, start using the iterator
version of dict.keys(), .values() and
.items(); avoid implict str and unicode coercions; use
__getitem__ instead of __setslice__; etc. Doing this
will decrease the amount of changes the 2to3 translator will have to do, and thus
reduce the chances of introducing new bugs.

Once you are done with that, you now ready to port your code to Python 3. This is where it become tricky. First, you will need to decide how you will maintain the Python 3 version of your project.
There is three main possibilities at this point. You can, for one, remove support for Python 2 and move your project completely to Python 3. This is not good idea if you already have a lot of users (in the case of a library).
Another possibility is to modify your code so that the 2to3 tool can translate it, without manual intervention, to a working Python 3 version. This is approach recommended by Python's core-devel team if you maintains a library that needs to support both Python 2.6 and Python 3. So when you do changes to your code, you edit the Python 2.6 version and run the 2to3 tool again to forward your changes, rather than editing the Python 3 version of the source code. This approach works, but I find it unnecessarily painful as you still end up maintaining a lot of crufts.
So, the approach I prefer is to create a separate branch for Python 3 and start maintaining two lines of development. This works great if you use one of these fancy DVCSs, as you can do your changes in the Python 2 branch and then forward your changes to the Python 3 branch by simply merging them. And when there is incompatibilities, you can run 2to3 tool on Python 3 code and it will fix these for you. An advantage of this approach is it gives a change to clean up your code and remove, from the Python 3 version, all that backward-compatibility stuff you may have accumulated over the years. And for many projects, this will be the only acceptable approach (mainly because of the Unicode changes).
Now, I would like to demo some of the features that are available that will ease the transition to Python 3.
Ed. In this part, I have shown a short demo on how to use 2to3 to convert feedparser to Python 3.0. This portion of the presentation was not prepared in advance and was interactive. If you want to see it, you will need to watch the video.


Concluding remarks:
Ending note. If you appreciated the content of this presentation or have suggestions, let me know! I am currently planning to do another talk at Montreal Python about extending and interfacing external code with Python. This presentation would mostly cover how to write extension using the C API of Python. As you can imagine, preparing a good presentation is lot of work. So any encouragement is welcomed.